
 安徽股票配资
安徽股票配资
写在开头:一句宕机戳破的神话
8月18日,印度本土大模型BharatGPT的云端演示进行到第7分钟,后台突然弹出“DeepSeek服务不可用”。
官方称这是“瞬时并发过高”,但业内更愿意认可另一种说法:演示调用的底层算力实际是部署在新加坡的,印度本土的集群根本无法承受512张A100的并发负载。
一出现故障,“AI民族主义”最尴尬的两件事就同时摆在眼前:防火墙还没搭建好,城门却已经先被攻破了。
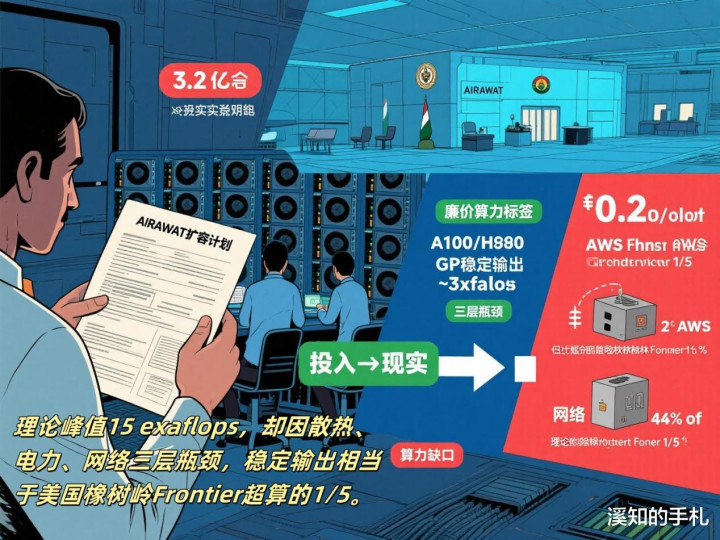
一、0.2美元/小时算力云:廉价背后的3.2亿美元学费
·政府投入:MeitY今年3月拨付3.2亿美元建设“AIRAWAT”扩容计划,目标是把公共算力池价格压到0.2美元/小时,仅为AWS同类实例的45%。
·现实骨感:目前实际可用GPU仅4,100张(A100/H100混布),理论峰值15 exaflops,却因散热、电力、网络三层瓶颈,稳定输出不到3 exaflops——相当于美国橡树岭Frontier超算的1/5。

·连锁反应:为了赶上BharatGPT的发布时间,运营那方偷偷把30%的训练负载挪到新加坡和东京的机房,结果就触发了“数据出境”警报不过演示总算是勉强过了第一轮媒体问答。

二、22种方言的“套壳”奇迹:80%代码仍姓“美”
·语言雄心:BharatGPT号称覆盖22种印度方言、5种文字,训练语料740GB,其中60%来自开源Common Crawl,20%为政府提供的印地语&泰米尔语行政文本。
·代码真相:GitHub热度最高的“BharatGPT-core”仓库里,80%关键模块直接fork自Meta LLaMA与Google PaLM2的早期开源版本;仅在最上层做了tokenizer与prompt-engineering的“印度化”封装。
·行业暗语:“二次封装”在班加罗尔被称为“Desi Wrapper”,开发者自嘲:“我们只是把咖喱味喷进GPT。”

三、数据本地化vs算力荒:放行A100转口,制裁红线若隐若现
·法规:2023年《数字个人数据保护法》要求“关键AI训练数据”必须存储在境内;这个时候印度对单张GPU功耗>400W的进口许可证实行年度总量控制。
·漏洞:出现在此处,为填补算力缺口,印度贸易商通过越南及阿联酋转口2800张A100,报关时将品名写成“图形工作站部件”,7月美国商务部向Nvidia去信,要求确认终端用户。
·风险:要是触发二级制裁,AIRAWAT二期的12000张H100订单很可能没了,BARC和ISRO的AI训练集群也会受影响。
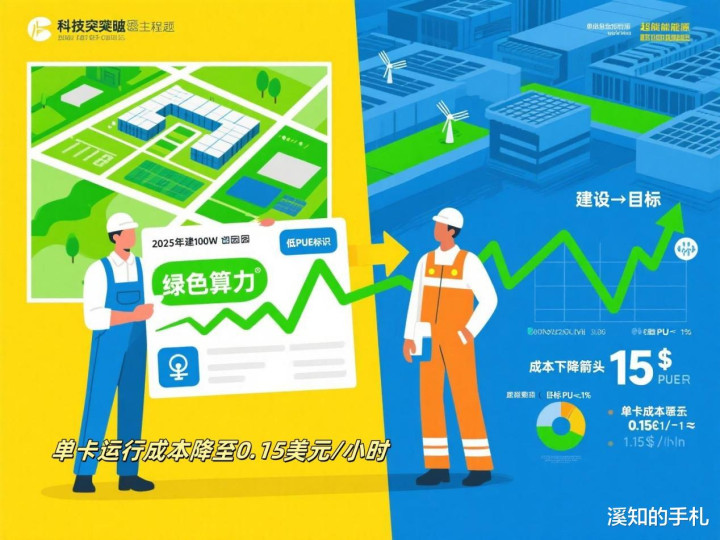
四、突围路径:从“二次封装”到“原创引擎”的三把钥匙
1.算力主权
·2025年前建成100 MW绿色超算园区(奥里萨邦),直连再生能源微网,目标PUE

2.开源根模型
·由IIT孟买牵头,联合8所IISC启动“Indus-1”计划,完全重写transformer内核,采用国产RISC-V指令集扩展,预计2026年放出2000亿参数开源底座。
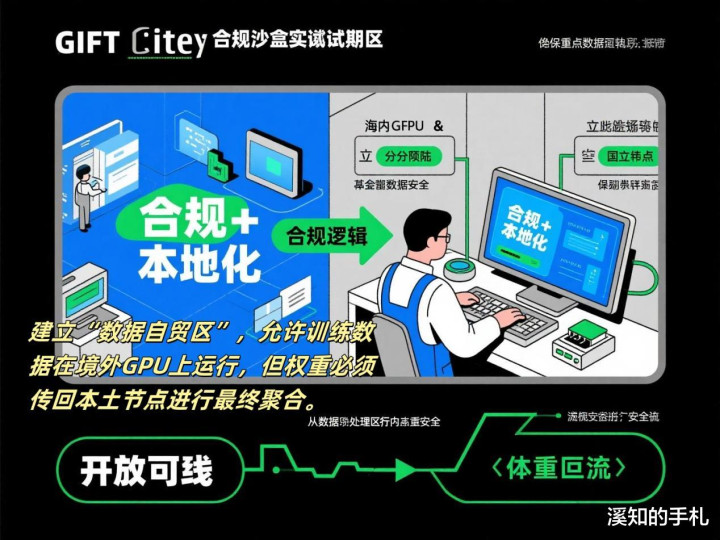
3.合规沙盒
·在GIFT City建立“数据自贸区”,允许经过差分隐私和联邦学习处理的训练数据在境外GPU上运行,但是权重必须传回本土节点进行最终聚合,这样既避开制裁又符合本地化需求。

结语:玻璃天花板还是跳台?
当“数据民族主义”遇上“算法附庸”,印度所面临的并不是一道明确的防火墙,而更像是一块透明的玻璃天花板:虽然能够看到全球市场,但却无法触及核心技术。
要是把算力主权、根模型创新还有合规沙盒组合成所谓的“AI新政”,把“二次封装”转化成“原创引擎”,那玻璃天花板才极有可能成为技术主权的一个跳板。
否则下一次宕机,或许连解释的理由都会“404 Not Found”。
声明:本文内容 90% 以上基于自己原创,少量素材借助 AI 辅助,但是所有内容都经过自己严格审核和复核。图片素材全部都是来源真实素材或者 AI 原创。文章旨在倡导社会正能量,无低俗等不良引导,望读者知悉。
参考资料:
《印度 AIRAWAT 公共算力池建设与运营报告(2024 年)》
《印度数字个人数据保护法实施细则(2023 年)》
《美国商务部关于 AI 芯片出口管制的政策解读(2024 年)》
《印度绿色超算发展规划与实施进展报告(2024 年)》
《Indus-1 计划技术白皮书(2024 年)》
《印度 GIFT City 数据自贸区政策框架(2024 年)》安徽股票配资
配先查提示:文章来自网络,不代表本站观点。
相关文章



推荐资讯